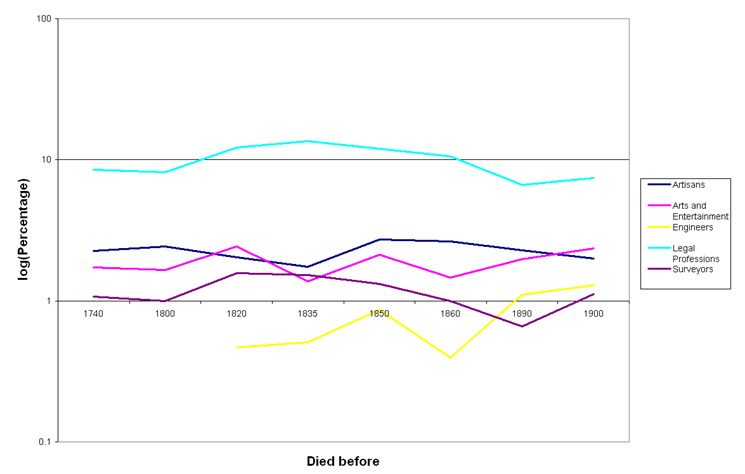
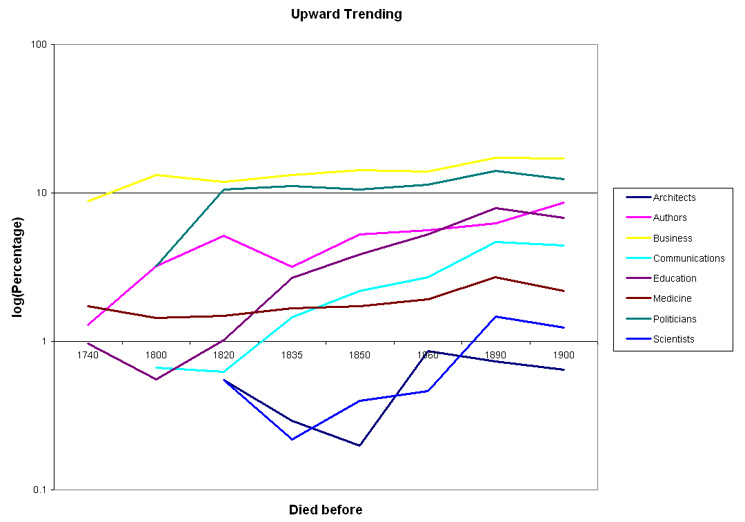
At this point it is probably a good idea to sketch out where we are going. The basic idea in text mining is to represent the features of a collection of documents in such a way as to facilitate further processing. Each of our documents is a biography of some person in the DCB. Each feature is something that the biography may or may not share with other biographies, like the presence of a particular word.
We can imagine this in the form of a simple spreadsheet, with a '1' if a particular word appears in the biography and a '0' if not:
| Name | Quebec | HBC | Acadia |
| Abraham, John | 1 | 1 | 0 |
| Aernoutsz, Jurriaen | 0 | 0 | 1 |
| Agariata | 1 | 0 | 0 |
Many machine learning algorithms have been developed to work with this kind of representation, and it will be fairly straightforward to generate from our biographies.
At this point, however, it is not clear where the features come from. We could try to use every word that appears in at least one biography, but that would not be very effective. For one thing, there are 592 biographies in volume 1, so the total number of distinct words will be quite high. For another, some words (like 'the', 'a', 'and') will be so common that they will not provide much useful information.
In the future, we will explore methods to generate the list of features automatically. For now, we are going to use a commercial program to generate a concordance. A concordance tells us how frequently every single word occurs in the collection of biographies and lets us explore the contexts where it does.
Some of the information that we can extract from the concordance will be quite interesting. For example, since each date is treated as a word by the software, we can figure out which dates occur in the biographies more frequently than others. Before we do this calculation, we can make a few predictions. Since historians like round numbers, we expect that decades will tend to be more popular than surrounding years. If you know that something happened in the late 1630s or early 1640s, you are more like to write "around 1640" than "around 1639." The second prediction that we can make is that later dates will be more common than earlier ones. The closer you get to the present, the more people there are and the more we know about them on average. Finally, since the DCB is arranged by death dates, and since we haven't included any biographies from Volume 2, we expect the dates to taper off near AD 1700 (as people in Volume 1 die). A smooth curve plotted through the number of times each date occurs in Volume 1 looks like the following figure.
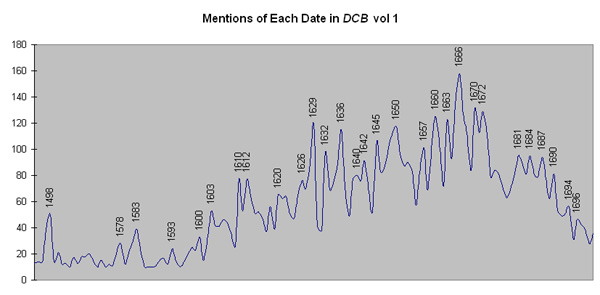
The curve looks pretty much like we expected it to. There are peaks at 1600, 1610, 1620 and most of the other decades in the seventeenth century. If we set those aside, we are left with a series of dates which may or may not be significant in early Canadian history: 1498, 1578, 1583, and so on. The most prominent seems to be 1666. In a future hack, we will try to automatically extract dates and match them against timelines from another source. For now it is sufficient to note that many of the peak dates coincide with well-known events in Early Canada. 1498 was the year of Cabot's second voyage, for example, and 1663 the year that the French crown took control of New France.
Next we will use the concordance to establish a list of features so we can create a spreadsheet representation of Volume 1 that looks like the one above...
Tags: concordance | dictionary of canadian biography | digital history | hacking | perl | statistical natural language processing | text mining