In November 2005, Amazon.com introduced a new web services API called Mechanical Turk. "When we think of interfaces between human beings and computers," someone at the company wrote, "we usually assume that the human being is the one requesting that a task be completed, and the computer is completing the task and providing the results. What if this process was reversed and a computer program could ask a human being to perform a task and return the results? What if it could coordinate many human beings to perform a task?" The way that the Amazon service works is for companies to submit tasks to a website and collect the completed results, exactly as they do when dealing with a traditional web service provided by machine. "Behind the scenes, a network of humans fuels this artificial, artificial intelligence by coming to the web site, searching for and completing tasks, and receiving payment for their work." There are a number of very interesting blogs (like Turk Lurker and Mechanical Turk Monitor) that give us a view of what is going on inside the automaton. And, of course, the service has also given rise to a range of intelligent and amusing commentary, such as Humans in the Loop, Web 2.0 is People! and Mechanical Turk.
The Amazon service is named after a late 18th-century automaton that played chess as well as a human being, or at least as well as the human being that was cleverly concealed inside the device. [Image; Refs: 12] Eventually it was denounced as a hoax. Its successors have been more successful. IBM's Deep Blue, for example, famously beat reigning world chess champion Garry Kasparov in 1996. Arguably, however, these later machines also contained people in the sense that human beings were required to build hardware, program software, prepare input, interpret output, and so on. Simply by ascribing meaning to computation, people become an essential part of the process. What the mechanical turks do—either the original or its namesake—is make it obvious that there are, as one formulation puts it, "humans in the loop."
So what does this have to do with history? For one thing, automata have a wonderful history of their own. The human sciences, too, have consistently drawn on contemporary understandings of mechanical or physical processes to create metaphors for cognition. In The Closed World (Cambridge, MA: MIT 1996), Paul Edwards argues that
Cognitive theories, like computer technology, were first created to assist in mechanizing military tasks previously performed by human beings. Complete automation of most of these activities—such as aiming antiaircraft guns or planning air defense tactics—was not a realistic possibility in the 1940s and 1950s. Instead, computers would perform part of the task while humans, often in intimate linkage with the machines, did the rest. Effective human-machine integration required that people and machines be comprehended in similar terms, so that human-machine systems could be engineered to maximize the performance of both kinds of components. [147]
Setting aside the history of computers and the history of people-as-computers, digital history allows people to be integrated into computation in surprising and powerful new ways. Many of these will have implications for public history. Take the folksonomies that arise from tagging. As Mills Kelly noted in a recent post in edwired, opening up archives and museums to public tagging is a new way of allowing people to find their own significance in historical sources. "Then we'll see what the archive really looks like to the user," he says, "as opposed to the archivist." Such a move could not only give curators and archivists a better idea of what their patrons think, but give professors a better idea of what their students think, and give students of social cognition a better idea of how people think. (And, of course, large repositories of tags lend themselves to data mining.) Best of all, Kelly and his colleagues will be developing their new website on the collapse of communism in eastern Europe so that users can do their own tagging.
For the past few weeks I've been thinking about a couple of different digital history projects and they seem to be leading in the same direction. On the one hand, I've been working on data mining the online version of the Dictionary of Canadian Biography as outlined here in a series of posts [1, 2, 3, 4, 5, 6]. On the other, I've been toying with the idea of reverse engineering Dan Cohen's H-Bot. (I'm sure Dan would share the algorithm or code with me if I asked, but I'm in the process of designing a graduate course in digital history and I'd like to find some reasonable assignments for my students. The best way for me to know if something is reasonable or not is to try to do it myself.) Anyway, both projects have led me to the apparently simple but surprisingly deep idea of data compression.
Many of the sources that historians use are documents written in a natural language. For example, on 19 August 1629, Sir George Calvert, Lord Baltimore wrote the following passage in a letter to King Charles I, explaining why he wanted to leave the colony of Avalon in Newfoundland and 'remove' himself to Virginia.
from the middest of October to the middest of May there is a sad face of winter upon all this land, both sea and land so frozen for the greatest part of the time as they are not penetrable, no plant or vegetable thing appearing out of the earth until it be about the beginning of May, nor fish in the sea, besides the air so intolerable cold as it is hardly to be endured
Natural languages are relatively redundant, which allows some of the information to be removed without loss of meaning. Written vowels, for example, can often be predicted from the surrounding context. The passage above has 371 characters, including the blank spaces. Even after we remove about one fifth of the characters, we can still pretty much read the passage.
frm th midst f Oct to th midst f May thrs a sad face of wntr upn al ths lnd, bth sea nd land so frzn fr th grtst prt f th time as thy r not pentrbl, no plnt r vegtbl thing appearng out f th erth til it be abt th beginng f May, nor fsh n th sea, bsides th air so ntolrbl cold as tis hrdly to be endurd
In this case, the 'compression' that I applied simply consisted of me crossing out as many characters as I could without making individual words indistinguishable from similar ones in context. Not very scientific. Alternately, we could use the frequencies of common English words as part of our code. Since 'of' is more frequent than 'if', we could use 'f' for the former; since 'in' is more frequent than 'an' or 'on' we could write 'n' vs. 'an' vs. 'on'. And so on. The important thing here is that both my naive method and the code based on frequencies rely on knowledge of English. English frequencies wouldn't be as useful for compressing French or Cree, and since I can't read Cree the results would suboptimal if I simply started crossing out random characters. Furthermore, neither method would be of any use for compressing, say, music files. Of more use would be a general-purpose compressor that could be implemented on a computer and would work on any string of bits. This is exactly what programs like bzip2 do.
Here is where it starts to get interesting. When confronted with a string that is truly random, the compressor can't make it any smaller. That is to say that the shortest description of a random string is the string itself. Most data, however, including data about physical systems, are full of regularities. In An Introduction to Kolmogorov Complexity and Its Applications, Ming Li and Paul Vitányi write
Learning, in general, appears to involve compression of observed data or the results of experiments. It may be assumed that this holds both for the organisms that learn, as well as for the phenomena that are being learned. If the learner can't compress the data, he or she doesn't learn. If the data are not regular enough to be compressed, the phenomenon that produces the data is random, and its description does not add value to the data of generalizing or predictive nature. [583]
Science may be regarded as the art of data compression. Compression of a great number of experimental data into the form of a short natural law yields an increase in predictive power... [585]
So what does this have to do with digital history? For one thing, as Dan Cohen explains in a couple of recent papers [1, 2] H-Bot makes use of some of the mathematics underlying data compression. For another, Rudi Cilibrasi and Paul Vitányi have recently shown that compression can be used as a universal method for clustering, one that doesn't require any domain knowledge. It works remarkably well on natural language texts, music files, genomes, and many other kinds of representation ["Clustering by Compression," IEEE Transactions on Information Theory 51, no. 4 (2005): 1523-45, PDF].
Their system is fairly easy to understand at an intuitive level, as long as you know that compressors are good at dealing with exact replications. If we use C(x) to denote the length of the compressed version of x, then for a reasonable compressor, C(xx) = C(x). Once you compress two copies of xjammed together, you should end up with something that is as long as the compressed version of x. To compute the similarity between two strings x and y, Cilibrasi and Vitányi define the Normalized Compression Distance as follows:
NCD(x,y) = [ C(xy) - C(x) ] / C(y)
(This version of the formula assumes that y is the string that is longer when compressed.) Now suppose we try this formula for two identical strings, and for convenience, let's assume that each has a compressed length of one unit.
The distance between identical strings is 0. Suppose we try the formula for two strings that are completely different. In other words, C(xy) = C(x) + C(y).
NCD(x,y) = [ C(xy) - C(x) ] / C(y) = (2-1)/1 = 1.
The distance between maximally different strings is 1. (For technical reasons, it is actually 1 plus some small error term ε.) Most interesting cases, however, will lie in between identity (NCD = 0) and complete difference (NCD = 1 + ε). In these cases, C(x) < C(xy) < C(x) + C(y). Intuitively, whatever x and y have in common makes C(xy) smaller than simply adding C(x) and C(y). Or, to put it more provocatively, what the compressor 'learns' by compressing x can be put to use when it compresses y, and vice versa.
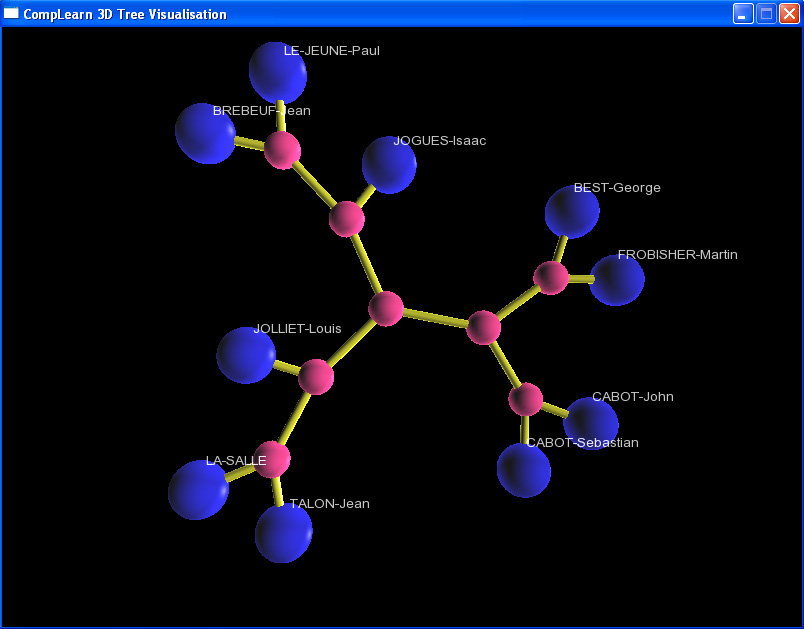
So how well does this method work on historical biographies? Fortunately, Cilibrasi and Vitányi have made their work available as an open source software package called CompLearn. I chose the biographies of ten individuals from the DCB and handed them off to CompLearn. (The individuals were George Best, Jean de Brébeuf, John Cabot, Sebastian Cabot, Martin Frobisher, Isaac Jogues, Louis Jolliet, René-Robert Cavelier de La Salle, Paul Le Jeune, and Jean Talon). If you are familiar with the history of Early Canada, you can probably do a preliminary clustering in your head. If not, a quick read through the biographies will give you some idea of how the individuals in question were related. The figure below shows what CompLearn came up with.
I have to say, I'm ridiculously excited about compression as a machine learning technique.
Most professors get paid for some agreed-upon mix of research, teaching and service. I've spent most of my time in this blog making a case for the ways that web programming can and will change the research and teaching of history. This week, however, I had the unexpected pleasure of doing a little service-related hacking.
Like every graduate program in the province, our department is subject to periodic review by the Ontario Council on Graduate Studies. One of the things that we thought might be useful was to try to find ways to assess the suitability of our library holdings for various kinds of historical projects. My colleague Allyson May had the good idea of checking books reviewed on various H-Net lists against our library holdings. Unlike regular journals, H-Net reviews tend to come out much more quickly, and thus are a better measure of recent literature of interest to historians. Of course, there are 170 H-Net discussion lists, some defunct, some with hundreds of book reviews over the last 13 years, and some with none. If you think this doesn't sound like something you'd want to do by hand, you're right.
In the following two hacks we automate the process. First, we go to the page of H-Net lists and get the name of each discussion list. The we go to the review search page, and, one-by-one, we search for all of the book reviews published on each discussion list. We save the links to each individual book review. We then spider the reviews, scrape the ISBN out of each, and save it to a file. Then, we submit each of the ISBNs to our library catalogue, and do a bit of rudimentary scraping to see if each book is in the library or not. Finally, we can accumulate the final results in a spreadsheet for whatever further analysis is required.
A few days ago, Mills noted that his excellent blog edwired (devoted to teaching and learning history online) ranked 217,330 at Technorati. Coincidentally, or perhaps not, Digital History Hacks had the exact same Technorati rank that day. Monitoring the ranking of a number of digital history blogs over the span of a few weeks, I've noticed that they rise and fall with respect to one another, but they also tend to rise or fall in absolute terms. I'm sure this isn't a new idea, but I got to wondering about creating something like a composite index for blogs (like the Dow-Jones or Nasdaq). One could check in and see not only how individual blogs were doing, but how (say) history blogs were doing in a relative sense. Like I say, I'm sure someone has already done this ... please feel free to e-mail me and let me know.
In my last update on this project I said that I was in the process of moving the Dictionary of Canadian Biography stuff to a relational database to allow more sophisticated mining. At this point it is worth sketching out some of the kinds of things that we would like the system to do, and how that affects the design of the database tables.
Imagine for a moment that we wanted to find more information relating to a particular figure in Early Canada, such as Médard Chouart Des Groseilliers, known to Canadian schoolchildren as "Gooseberry" ... or at least to those who remember their history. Anyway, we could type 'groseilliers' into Google and see what we get. As of this moment, there are 46,700 hits. The first 10 are all relevant, coming from Collections Canada, a PBS series on the HBC, various encyclopedias and so on. If we were looking for information related to Des Groseilliers's companion Pierre-Esprit Radisson, a comparable search now turns up fourteen and a half million hits. The first twenty hits are all related to the Radisson hotel chain. In fact, the Radisson Hotel in Kathmandu (someplace I've never been, incidently) receives a higher billing in the search results than our lowly explorer. Both "Groseilliers" and "Radisson" are relatively distinctive names, however. What if we were interested in someone like John Abraham (fl 1672-89), governor of Port Nelson? Since both "John" and "Abraham" are common names, and since both can serve as either personal name or surname, we know that a Google search is probably going to be more-or-less useless (and in fact returns 21.5 million hits).
We'd obviously like to be able to pull needles like John Abraham out of the haystack, and this is where data mining comes in. One branch of the discipline concentrates on a group of related techniques known variously as link analysis, social network analysis and graph mining. (Papers from past SIAM conferences on data mining are a nice source of information, available online.) The basic idea is fairly straightforward. We know that the John Abraham that we are interested in lived in the late 17th century, operated in a variety of locations around Hudson Bay, and knew various other individuals like Charles Bayly, John Nixon, Nehemiah Walker, John-Baptiste Chouart, George Geyer and others. We know that he was mate of the Diligence in 1681, captain of the George and that he helped capture the Expectation in 1683. If we bring in some of this additional information, we might be able to refine our search to the point where it yields something interesting. If we Google for "+john +abraham hbc nehemiah nixon diligence" we now find that we get a total of 10 hits, 5 of which are relevant. This is a nice way to distill our search results into something more useful, but it is still underpowered in two senses. First, we had to do it by hand, thus violating the programmer's cardinal virtue of laziness. Second, we still haven't exploited the fact that we know something about the network that John Abraham was embedded in.
What does that mean? Abraham's biography mentions John Marsh, who was appointed governor of James Bay in 1688 and died that year or the following. And Marsh's biography mentions William Bond (fl 1655-94), captain of the Churchill. Now although Abraham's biography doesn't mention Bond at all, when we read Bond's biography we discover that he found the Mary in distress in Hudson Strait and took her company aboard, including John Abraham. Abraham's biography mentions that the Mary was wrecked by ice, but doesn't mention Bond. By following the links between various entites (people and ships in this case), we were able to discover new information. Techniques for link analysis automate this process of discovery.
So what kind of database tables do we need? We want to keep each kind of entity in a separate table. We will have one table each for people, places, ships, documents, institutions, and so on. Each individual in one of these tables must be distinguished from all of the others, so we create what is called a primary key for each. Your name, which is not guaranteed to be unique, isn't a good primary key (think of "John Abraham"). Your social insurance number (or social security number) is supposed to be. We will just assign these primary keys automatically. Whenever we need information about one of our entities, we can look it up using the primary key.
We will also want to create tables of links. These will contain a primary key (something to specify each unique link) and foreign keys for each entity that is linked. So, schematically, one entry in our link table might say "the person John Abraham is related to the ship Mary" (and specify how), and another might say that "the person William Bond is related to the institution HBC," and so on. We can then write programs to trace along these links trying to discover new information, or programs that can refine search results by drawing in related information.
I've spent the past few weeks putting the finishing touches on a book manuscript that I am submitting now for peer review. It's been fun, but I'm looking forward to getting back to coding. So more digital history hacking soon...
Are you interested in learning how to program? Check out The Programming Historian, an open-access introduction to Python programming for working historians (and other humanists) with little previous experience.

{kind=link}