Many of the sources that historians use are documents written in a natural language. For example, on 19 August 1629, Sir George Calvert, Lord Baltimore wrote the following passage in a letter to King Charles I, explaining why he wanted to leave the colony of Avalon in Newfoundland and 'remove' himself to Virginia.
from the middest of October to the middest of May there is a sad face of winter upon all this land, both sea and land so frozen for the greatest part of the time as they are not penetrable, no plant or vegetable thing appearing out of the earth until it be about the beginning of May, nor fish in the sea, besides the air so intolerable cold as it is hardly to be endured
Natural languages are relatively redundant, which allows some of the information to be removed without loss of meaning. Written vowels, for example, can often be predicted from the surrounding context. The passage above has 371 characters, including the blank spaces. Even after we remove about one fifth of the characters, we can still pretty much read the passage.
frm th midst f Oct to th midst f May thrs a sad face of wntr upn al ths lnd, bth sea nd land so frzn fr th grtst prt f th time as thy r not pentrbl, no plnt r vegtbl thing appearng out f th erth til it be abt th beginng f May, nor fsh n th sea, bsides th air so ntolrbl cold as tis hrdly to be endurd
In this case, the 'compression' that I applied simply consisted of me crossing out as many characters as I could without making individual words indistinguishable from similar ones in context. Not very scientific. Alternately, we could use the frequencies of common English words as part of our code. Since 'of' is more frequent than 'if', we could use 'f' for the former; since 'in' is more frequent than 'an' or 'on' we could write 'n' vs. 'an' vs. 'on'. And so on. The important thing here is that both my naive method and the code based on frequencies rely on knowledge of English. English frequencies wouldn't be as useful for compressing French or Cree, and since I can't read Cree the results would suboptimal if I simply started crossing out random characters. Furthermore, neither method would be of any use for compressing, say, music files. Of more use would be a general-purpose compressor that could be implemented on a computer and would work on any string of bits. This is exactly what programs like bzip2 do.
Here is where it starts to get interesting. When confronted with a string that is truly random, the compressor can't make it any smaller. That is to say that the shortest description of a random string is the string itself. Most data, however, including data about physical systems, are full of regularities. In An Introduction to Kolmogorov Complexity and Its Applications, Ming Li and Paul Vitányi write
Learning, in general, appears to involve compression of observed data or the results of experiments. It may be assumed that this holds both for the organisms that learn, as well as for the phenomena that are being learned. If the learner can't compress the data, he or she doesn't learn. If the data are not regular enough to be compressed, the phenomenon that produces the data is random, and its description does not add value to the data of generalizing or predictive nature. [583]
Science may be regarded as the art of data compression. Compression of a great number of experimental data into the form of a short natural law yields an increase in predictive power... [585]
So what does this have to do with digital history? For one thing, as Dan Cohen explains in a couple of recent papers [1, 2] H-Bot makes use of some of the mathematics underlying data compression. For another, Rudi Cilibrasi and Paul Vitányi have recently shown that compression can be used as a universal method for clustering, one that doesn't require any domain knowledge. It works remarkably well on natural language texts, music files, genomes, and many other kinds of representation ["Clustering by Compression," IEEE Transactions on Information Theory 51, no. 4 (2005): 1523-45, PDF].
Their system is fairly easy to understand at an intuitive level, as long as you know that compressors are good at dealing with exact replications. If we use C(x) to denote the length of the compressed version of x, then for a reasonable compressor, C(xx) = C(x). Once you compress two copies of x jammed together, you should end up with something that is as long as the compressed version of x. To compute the similarity between two strings x and y, Cilibrasi and Vitányi define the Normalized Compression Distance as follows:
NCD(x,y) = [ C(xy) - C(x) ] / C(y)
(This version of the formula assumes that y is the string that is longer when compressed.) Now suppose we try this formula for two identical strings, and for convenience, let's assume that each has a compressed length of one unit.
NCD(x,x) = [ C(xx) - C(x) ] / C(x) = [ C(x) - C(x) ] / C(x) = 0 / 1 = 0
The distance between identical strings is 0. Suppose we try the formula for two strings that are completely different. In other words, C(xy) = C(x) + C(y).
NCD(x,y) = [ C(xy) - C(x) ] / C(y) = (2-1)/1 = 1.
The distance between maximally different strings is 1. (For technical reasons, it is actually 1 plus some small error term ε.) Most interesting cases, however, will lie in between identity (NCD = 0) and complete difference (NCD = 1 + ε). In these cases, C(x) < C(xy) < C(x) + C(y). Intuitively, whatever x and y have in common makes C(xy) smaller than simply adding C(x) and C(y). Or, to put it more provocatively, what the compressor 'learns' by compressing x can be put to use when it compresses y, and vice versa.
So how well does this method work on historical biographies? Fortunately, Cilibrasi and Vitányi have made their work available as an open source software package called CompLearn. I chose the biographies of ten individuals from the DCB and handed them off to CompLearn. (The individuals were George Best, Jean de Brébeuf, John Cabot, Sebastian Cabot, Martin Frobisher, Isaac Jogues, Louis Jolliet, René-Robert Cavelier de La Salle, Paul Le Jeune, and Jean Talon). If you are familiar with the history of Early Canada, you can probably do a preliminary clustering in your head. If not, a quick read through the biographies will give you some idea of how the individuals in question were related. The figure below shows what CompLearn came up with.
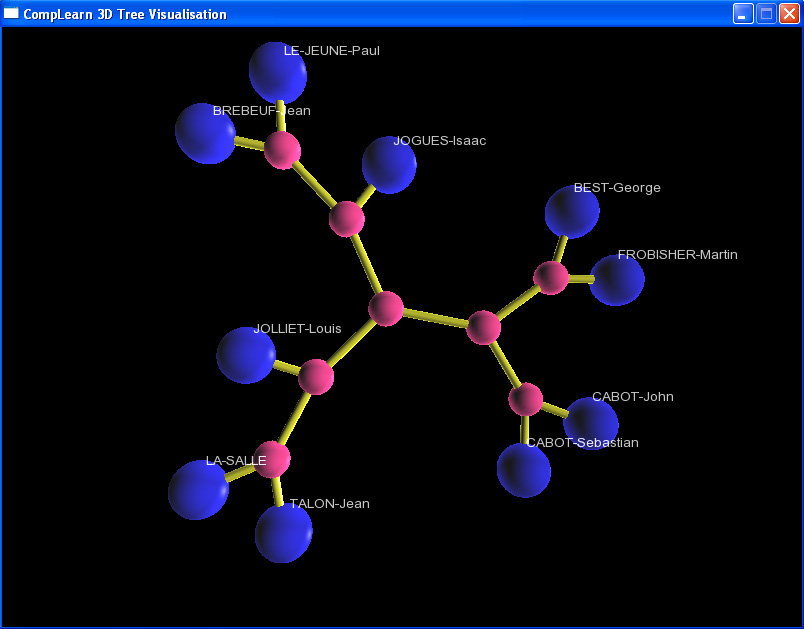
I have to say, I'm ridiculously excited about compression as a machine learning technique.
Tags: data compression | data mining | dictionary of canadian biography | digital history | Kolmogorov complexity | open source | visualization
